
9 approaches to conversational intelligence
Different models of conversational intelligence tradeoff performance, developer effort and controllability. Which model are you using?
There are many choices of models for your conversational AI, and understanding these choices can help you make the decision between using a pre-existing framework or implementing your own. We will describe nine approaches; however, before we begin, let’s have a look at the foundational concepts of behavior and intelligence referred to throughout this article.
Behavior as stimulus and response
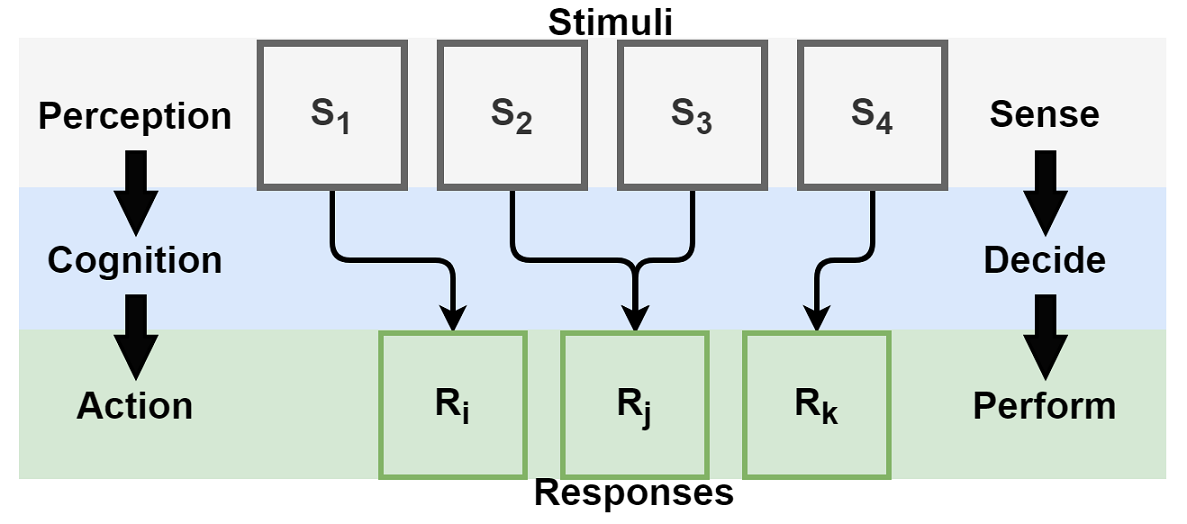
A simple way of describing agent behavior is a mapping from stimulus to response. Consider the following human and machine behaviors:
| Stimulus | Response | |
|---|---|---|
| Button pressed | → | Bell rings |
| Browser icon clicked | → | Launch browser |
| Heard “Congratulations” | → | Says “Thanks” |
| Heard “Thanks” | → | Says “You’re welcome” |
| Detected speech “Hey Google” | → | Lights up |
| Identified intent:stop | → | Pause music player |
Three types of intelligent processes, perception, cognition and action, are chained together in this concept of behavior. Perception continuously senses stimuli from the environment. Cognition makes decisions using the perceived stimuli. Based on the decisions, a response may be produced. Action intelligence performs the response. Other agents, that could be users and systems, perceive these responses as new stimuli, which in turn, respond by invoking their own chains of intelligent processes. This repetition creates intelligent interaction.
Let’s apply this model of behavior to conversations. Perception is not only hearing and vision; but also sensing of time, prior state and context (e.g., user, application, network, location). In mainstream conversational AI systems, automatic speech recognition (ASR) and natural language understanding (NLU) are perceptual intelligence components. Natural language generation (NLG) and text-to-speech (TTS) perform action. Other perceptual components, such as addressee resolution, gaze tracking, emotion detection or gesture recognition, may be used in some systems. Similarly, other examples of actions include on-screen display, actuating a robot and calling an API.
Stimulus is processed into meaning bearing representations (e.g., words, parse trees, intents, slots, queries, one-hot vectors, embeddings). Cognition modules use the perceived stimulus to make decisions about if and how to respond. Cognitive conversational intelligence, which will be the focus of the rest of this article, can take the form of a dialog manager, a skill router, an orchestrator, a policy or a parameterized model. In order to make appropriate decisions, conversational intelligence needs to be customized to the application domain either manually or using data. Business logic and design specifications may be implemented in this module, and it is often necessary to have a high degree of control over it. While we will discuss nine prevalent ways of implementing conversational intelligence in this article, this list is not intended to be exhaustive. Instead, this article should serve as a reference for approaches to consider, their appropriate use and limitations.
Table lookup
Consumer hardware platforms and operating systems are increasingly AI enabled. Both Android and iOS devices are starting to offer high performing, on-device speech recognition (i.e., no need to stream speech to the cloud). Not only does this allow developers to eliminate recurring ASR costs, but it also offers the end-user greater speech data privacy, as speech may no longer need to be streamed out of the device.
A simple approach to conversational intelligence is to collect all viable inputs (stimuli) and corresponding responses in a table, so that cognition is reduced to table lookup. Using indexing for efficiency and partial matching for robustness can make this approach suitable for applications, like answering frequent user queries (FAQs) or delighting users with conversational easter eggs.
To use this approach, start with a corpus that has high coverage of user queries and corresponding responses. Invest in tools that support the workflows for lookup table maintenance and for monitoring user queries that go unresponded. As the corpus grows, models that index the collection of responses (i.e., documents) against expected user inputs (i.e., queries) get more sophisticated. This advanced approach transforms into retrieval-based conversational AI, which is discussed ahead under end-to-end approaches.
Dialog graphs
Graphical representations of conversations are most often used in entertainment and educational applications. These graphs, also referred to as scripts, flowcharts or paths, lead users through a system directed multi-turn conversation. Dialog graphs can support features like branching, conditioning, looping back and response variations. These features allow users to take alternate paths through the conversation. User input can be in the form of button clicks or natural language (spoken or typed). Due to the limited set of responses produced by this approach, it is often possible to employ voice actors to record high quality performances of spoken output, when suitable.
Dialog graphs are a simple extension of the table lookup approach. The user input representation combined with recently visited graph node(s) are used to lookup the response. Existing authoring tools for visualizing and editing directed graphs can be readily used to create dialog graphs. These tools make it possible to engage content creators who need not be programmers into the process. Dialog graphs are easy to maintain and afford total control to developers.
Finite state machines
State machines offer powerful formalism for describing and implementing the behaviors of numerous conversational skills. Consider a conversational shopping experience; users search for items on their list, select from a list of matching items and add them to the cart. The process repeats until the user is ready to check out. Simplistically, this can be modeled as the following two-state machine, which can be extended to make the conversational skill more feature complete.
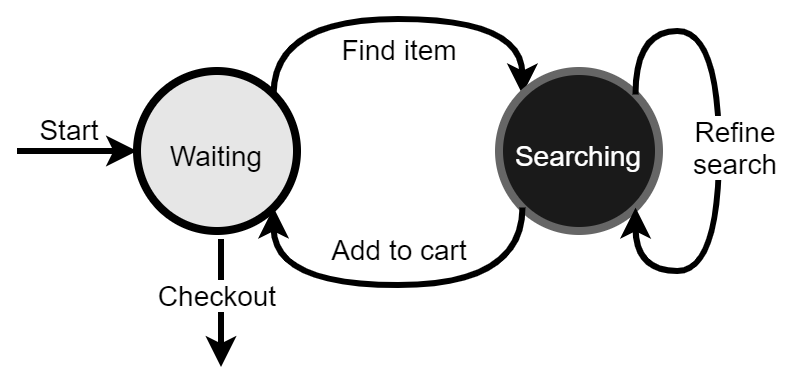
Perceptual intelligence (e.g., an intent classifier) triggers state transitions. In addition to user input, transitions can be triggered by timeouts and contextual cues. When necessary, slot extraction can be used to collect additional information from user input (e.g., item descriptions). Valid transitions update the current state after producing specified actions, like a prompt or an API call.
Suitable for most “skill-sized” conversations, the limitations of finite state approaches start to show as the number of states and actions grow. Larger state space leads to a combinatorial explosion making these finite state machines increasingly difficult to maintain. It is best to decompose complex finite state based conversations into multiple smaller, more easily maintained machines. The practical implementation of this approach requires thoughtful implementation of a mechanism to persist conversational state across multi-turn interactions when deployed on distributed infrastructure (e.g., cloud).
Form filling

Business applications such as booking a hotel, flight or a train, making reservations and searching a multi-attribute product (e.g., a car), fit the form filling approach of conversational AI. Users specify one or more of a set of expected inputs (e.g., date, time, location, count, identifier) that are necessary to serve their request. The conversational intelligence can then elicit additional information (e.g., “where are you leaving from”), or update previously provided inputs through system-directed questions until the user’s request can be served, or the user gives up.
In contrast to the finite-state approach, form filling, also referred to as slot filling, eliminates the need for manually specifying states and transitions. By declaring the fields of the form along with some qualifiers (e.g., if the fields are optional, entity type, prompt templates), the functionality that would otherwise require a densely connected finite state machine can be implemented with ease, from the point of view of application designers and developers. As a byproduct of using form filling, users get a greater degree of flexibility in how they provide their inputs. Users can input multiple fields together in any order and even revise their inputs during the conversation.
Many contemporary conversational commerce applications fit into this mold. Because of the high business impact of this approach conversational AI toolkits support advanced functionality relevant to the form filling approach, including belief tracking, automatic confirmations and slot validation. It is advisable to use one of the many readily available conversational AI toolkits that supports form filling if you choose this approach for your application.
Goal-driven dialog
It must be noted that in recent literature, the use of the terms “goal-driven” and “goal-oriented” has been overloaded to refer to task focused conversational systems (in contrast to systems for social interaction like chit-chat and small talk). By goal driven dialog, we are referring to the conversation management approach, not the family of applications.
To reduce the need for explicitly specifying conversations in terms of dialog graphs, states and transitions, we can use the goal-driven dialog approach. Using declarative representations of the domain, as opposed to procedural representations of the task used in the previous approaches, a goal driven dialog approach can reduce the quantity of specification required for implementing complex domains. For example, instead of specifying the procedure for doing a transfer between two bank accounts, the funds_transfer goal may be specified in the following form:

In this specific framework of goal driven dialog, the conversation engine recursively scans the preconditions of the current goal and identifies other goals that can potentially satisfy remaining preconditions. An example of one such subgoals is below:
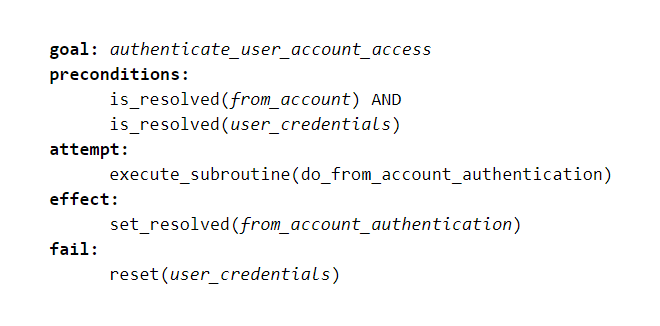
The specific form of declarative representation may vary in different systems. Fields specified in form filling are a form of declarative representation. The recursive goal identification process is old school AI which uses planning algorithms to dynamically generate an appropriate conversation script based on the current state. This process can generate a large variety of conversations without requiring the different dialog paths to be explicitly authored.
The goal-driven approach is suitable for applications where form-filing alone cannot specify the desirable conversational behaviors. Follow-on user queries like, “what’s my balance after this?” should not require refilling the entire form over again. Advanced capabilities, such as transferring recent field bindings make their way into form-filing based conversational AI toolkits when they have recurring value in mainstream use cases, like the ones mentioned above. The boundary keeps moving. In today’s practice goal-driven dialog approaches are often found in human-agent collaboration applications of conversational AI, such as co-construction or decision support.
Within the approaches discussed so far, we can see the spectrum of authored (i.e., no-code, low-code) and programmed approaches explicitly. In practice, as we move away from authoring based approaches, the development process becomes increasingly non-intuitive for conversation designers.
Knowledge driven dialog
Whether you are looking up a user’s account balance, or a flight’s schedule, the ability to query a database to respond to a user’s utterance is a frequent use case of conversational AI. Instead of using multiple application specific databases, knowledge graphs, also referred to as semantic networks, offer a general approach for representing the relationships between entities. Not only can knowledge graphs (KGs) represent heterogeneous application specific information (e.g., the packaging date and ingredients of a retail product), but they can also include factoids, such as “corn is gluten free” and “1 lb is 454 grams”.
KGs provide the ability to bring together different forms of information into one human readable & editable format. KGs are constructed by a combination of methods, including automatically extracting entities and their relationships from existing structured knowledge sources, like databases and knowledge bases; by parsing unstructured data, such as web pages; as well as manually adding knowledge using KG specific editing tools.
A knowledge driven approach to conversational AI infers answers to user queries by matching a parse of the user query to relationships present in the KG. Sophisticated KG algorithms can accurately answer complex queries even if it requires identifying and combining multiple links in the KG. In order to support multi-turn conversations, knowledge driven approaches must support the identification and resolution of referring expressions (e.g., “is that vegan?”). There are a number of limitations of knowledge driven conversational AI. Foremost, the responses generated by this approach are terse, typically, one word or short phrase, which may not be suitable for some user experiences (e.g., speech output). KGs also suffer from ambiguity because the same user expressions can refer to different elements of the KG, both entities as well as relationships.
Despite these shortcomings, the knowledge driven approach can fill in the gaps in your conversational AI enabled products by serving users with your existing knowledge sources. In practice, this approach is used in combination with one or more of the other conversational intelligence techniques listed in this article.
Policy learning
We now switch gears to a set of approaches that rely on availability of conversational data. This type of data is gathered by a variety of methods, including wizard-of-oz methods (i.e., a human pretends to be the conversational system and interacts with the user to collect data), human-human interaction (e.g., customer support logs) or from early prototypes of the system. Like all conversational AI cognition modules, a policy map perceived stimulus (e.g., inputs, state, contexts,time) to system action.
In the above approaches, the conversation policy is implicit, either in the algorithm or in the interaction design. Policy learning techniques, on the other hand, use available data to deduce a suitable mapping. Different policy learning techniques optimize different types of criteria. The use of various types of supervised machine learning algorithms for policy learning is very common; however, a concern is that those algorithms optimize the policy to pick the right action one turn at a time. If we think of a conversation as a game of chess, where the goal is to successfully complete the conversational task, it is desirable to optimize for the outcome of the entire conversation.
Reinforcement learning (RL) techniques have the ability to maximize a delayed reward that is known only after several steps. Applications of RL to conversational policy learning are being actively pursued. In practice, training and maintaining with RL needs the ability to simulate user behavior that the RL algorithm can go head to head with as it learns. Creating a user simulation and a reward function can be just as resource intensive in terms of data, expertise and time. As your conversational dataset grows, it is advisable to build capacity within your organization and explore policy learning approaches, conduct A/B tests and deploy hybrid solutions that advance your business metrics.
End-to-end approaches
Unlike the earlier approaches to conversational intelligence, end-to-end approaches model conversations “end-to-end” (i.e., from perception to action). As such, we can consider this approach to be closest to the pure form of stimulus-response model. This approach is motivated by a desire to minimize handcrafting of conversational logic, as well as eliminating the building and maintenance effort of multiple domain specific components (e.g., NLU, NLG).
Successes in end-to-end (E2E) approaches have been through the use of massive volumes of language data, conversational or otherwise, and recent advances in machine learning; specifically, the ability to train neural networks that can efficiently represent user utterances, as well as conversational context. These efficient representations are mapped directly to responses sampled from the data using either generative and retrieval-based techniques. As the name suggests, generative approaches generate the response word by word. Retrieval based approaches, on the other hand, select, or more accurately, score and rank, from a set of responses included in the dataset. Within E2E approaches, retrieval-based conversational AI has been successful in chit-chat (i.e., social dialog applications). The recently released massive domain agnostic generative model, GPT-3, has demonstrated impressive applications to non-task specific conversational AI use-cases. Similar approaches have been demonstrated by Google.
These approaches are currently at the cutting edge of conversational AI research. The metrics used in research may not be reflective of the user benefit and business ROI. Typically, generative approaches have been known to create incoherent, repetitive and very general responses. On the other hand, retrieval based approaches can only produce responses from a pre-existing collection. Using E2E approaches in consumer facing products requires investment in dataset creation and experimentation time, both of which should happen in parallel. The availability of several open-source projects and on-demand model training infrastructure, available through cloud providers, makes it easy to get started on experimentation. You will need an existing dataset of application relevant conversations, or a method for synthetically generating one (e.g., by simulation).
It must be noted that E2E approaches shift the process of conversation design towards dataset creation. The ability to control the behavior of the conversational agent is distanced from the designer and developers due to the opaque nature of the underlying neural models. Organizations looking to utilize E2E approaches must find novel ways to maintain control over their conversational AI. The ability to combine different conversational models using multi-expert architectures, discussed below, can be helpful.
Routing & multi-expert approaches
Introduced into practice over two decades ago, the idea of routing is at the heart of today’s large scale conversational AI platforms. A task specific module is activated based on an automated linguistic analysis of the user’s utterance. In modern NLUs, this linguistic analysis takes the form of an intent classifier, which may be built on top of a robust parser, as well as a machine learning model. The task specific modules are called by different names (skill, agent, capsule, behavior, route, expert) depending on the platform you use. One of the key ideas of the original routing approach, that still prevails, is the notion of pre-routing (i.e., the mapping from perceived symbols to modules are predetermined). In this approach, the modules have no ability to provide feedback to the router once the routing decision has been made. Only one module gets to execute and make decisions about responding to input.
Multi-expert approaches use post-routing. In this approach, multiple, often all, modules receive the user input. Each module can independently process the user input and context, apply domain specific logic, use its previous state, communicate with other modules and query external sources (using APIs) in order to generate a response. Modules are experts at one conversational capability, like reporting the weather, complimenting the user, telling a joke, etc.. As such, each module is precision-tuned (i.e., they respond only to module relevant stimuli). It is acceptable and expected that most modules will not produce a response for most inputs. The generated responses, along with their module specific features like confidence and relevance, are collected by the multi-expert router, which selects and sends a response to the user. A combination of hand-crafted rules and ranking models is used to select the response.
Multi-expert is essentially a meta approach to conversational intelligence. It is most suitable when multiple approaches listed earlier need to be combined to create a comprehensive conversational user experience. Microsoft’s Xiaoice chatbot, now independent, used this approach to bring together a large number of custom built skills that together create complex and engaging conversations. Multi-expert based approaches have been used in various entries to Amazon’s Alexa Socialbot competition. In general, routing approaches can manage the conversations that span multiple topics. Intermediate approaches between pre and post routing, as well as the extension of multi-expert approaches into decentralized behavior networks, have been studied as well.
One size does not fit all

As mentioned in the opening, the list of conversational intelligence approaches is intended to be illustrative, not exhaustive. We present a gradual progression of the ability to handle complexity. Each approach has its advantages, implementation costs and limitations. Applications that push the boundary of contemporary conversational AI require ongoing innovation. For example, applications where multiple users are participating in the same conversation, such as real-time translation and meeting assistants, require the ability to track the interaction between the users and make decisions to respond only when appropriate. In voice guided navigation applications, the machine cognition needs to monitor the context (location change) and proactively initiate new responses. Conversational AI embedded in robots requires a tight coordination between the realization of an action (i.e., response presentation) and the cognition to be able to react to environmental constraints.
Different levels of conversation management are stacked together in fully self contained systems. Just like high level interaction strategies, low-level interaction behaviors (e.g., swift turn-taking, back channel feedback, system initiation, incrementality), which make the conversational AI appear less clunky and more reactive, utilize many of the same approaches. The different layers coordinate with each other through triggers and interrupts, and together constitute a conversational operating system. Investments in full-stack conversational AI are necessary for building hardware platforms, or distributed infrastructure, for this technical area.
Elements of hybridization of multiple approaches are often visible in most existing conversational interfaces. Some toolkits and conversational AI authoring platforms unify two or more approaches to offer greater functionality to their developers. For example, in a recent update, Google’s DialogFlow CX has brought together form-filling based dialog with a finite-state machine approach.
As your organization advances in its preparation for the conversational UX paradigm, what may have started as an exploration into conversational AI will no longer remain as isolated features. From an engineering strategy point of view, sticking strictly to any one of the above approaches will quickly become overly-prescriptive; it will limit your teams from building what works best for their feature, and will gradually lead to a fractured user experience. Instead of centralizing conversational AI into one team, your technology strategy should enable development teams spread across your organization to build their own conversational features without stepping on each other’s toes. Conversational AI design, implementation, review and monitoring processes should be put in place to make sure that all of your overall UX is consistent, cohesive and compliant.
Contact
Whether you are just testing the waters of the conversational UX paradigm, or empowering your organization to win amidst change, we can help. VoiceThesis helps organizations accelerate their AI strategy. We create client ROI by demystifying tech and solving technical challenges that help clients create market relevant products and services.
Reach out to start an obligation free, exploratory discussion. You can email us directly: contact@voicethesis.com or use this contact form.